Evaluation (pymia.evaluation package)¶
The evaluation package provides metrics and evaluation functionalities for image segmentation, image reconstruction, and regression. The concept of the evaluation package is illustrated in the figure below.
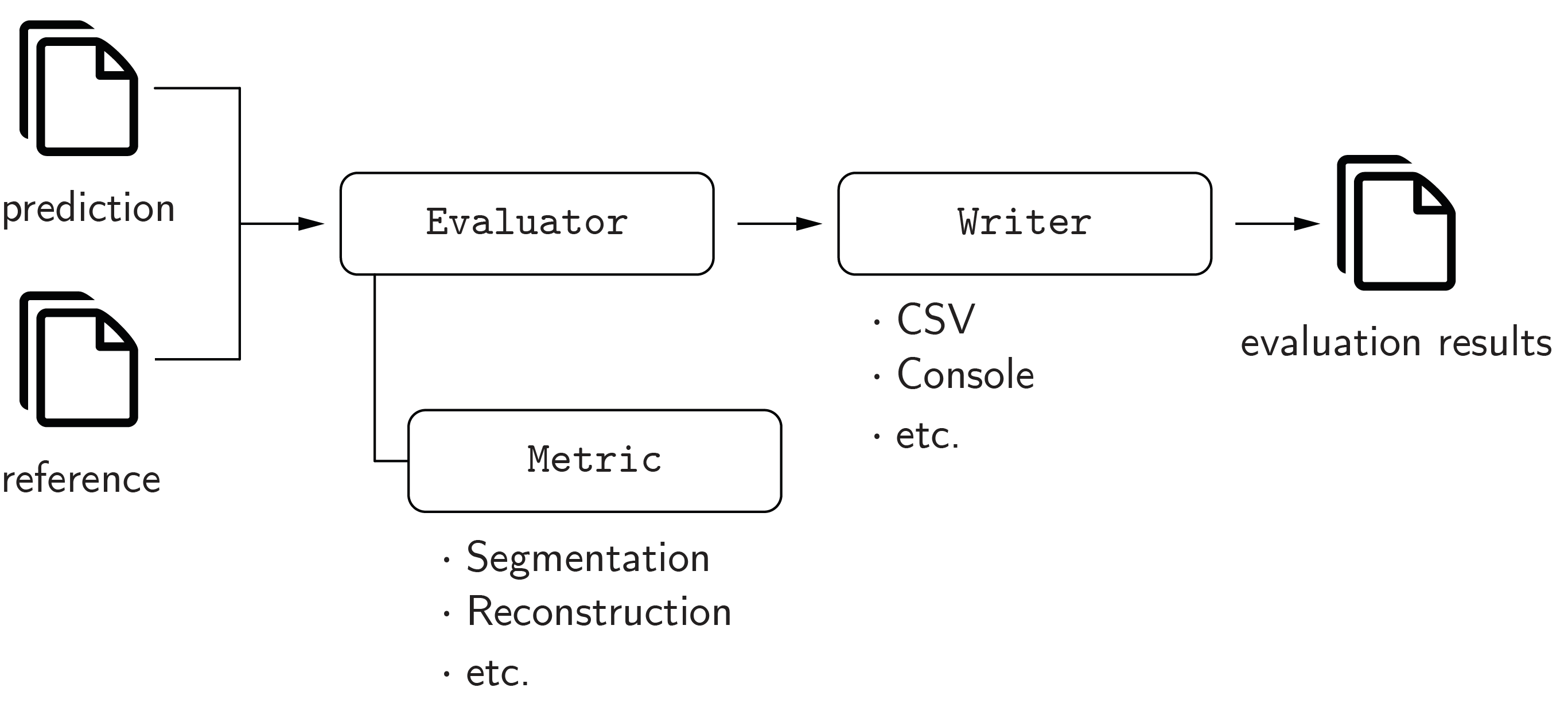
All metrics (pymia.evaluation.metric.metric package) implement the
pymia.evaluation.metric.base.Metric interface, and can be used with the pymia.evaluation.evaluator package
to evaluate results (e.g., with the pymia.evaluation.evaluator.SegmentationEvaluator).
The pymia.evaluation.writer package provides several writers to report the results, and statistics of the results,
to CSV files (e.g., the pymia.evaluation.writer.CSVWriter and pymia.evaluation.writer.CSVStatisticsWriter)
and the console (e.g., the pymia.evaluation.writer.ConsoleWriter and
pymia.evaluation.writer.ConsoleStatisticsWriter).
Refer to Evaluation of results for a code example on how to evaluate segmentation results. The code example Logging the training progress illustrates how to use the evaluation package to log results during the training of deep learning methods.
Subpackages¶
- Metric (
pymia.evaluation.metricpackage)- Base (
pymia.evaluation.metric.base) module - Metric (
pymia.evaluation.metric.metric) module - Categorical metrics (
pymia.evaluation.metric.categorical) moduleAccuracyAdjustedRandIndexAreaMetricAreaUnderCurveAverageDistanceCohenKappaCoefficientDiceCoefficientFMeasureFalloutFalseNegativeFalseNegativeRateFalsePositiveGlobalConsistencyErrorHausdorffDistanceInterclassCorrelationJaccardCoefficientMahalanobisDistanceMutualInformationPrecisionPredictionAreaPredictionVolumeProbabilisticDistanceRandIndexReferenceAreaReferenceVolumeSensitivitySpecificitySurfaceDiceOverlapSurfaceOverlapTrueNegativeTruePositiveVariationOfInformationVolumeMetricVolumeSimilarity
- Continuous metrics (
pymia.evaluation.metric.continuous) module
- Base (
The evaluator module (pymia.evaluation.evaluator)¶
The evaluator module provides classes to evaluate the metrics on predictions.
All evaluators inherit the pymia.evaluation.evaluator.Evaluator, which contains a list of results after
calling pymia.evaluation.evaluator.Evaluator.evaluate(). The results can be passed to a writer of the
pymia.evaluation.writer module.
- class pymia.evaluation.evaluator.Evaluator(metrics: List[Metric])[source]¶
Bases:
ABCEvaluator base class.
- Parameters:
metrics (list of pymia_metric.Metric) – A list of metrics.
- abstract evaluate(prediction: Image | ndarray, reference: Image | ndarray, id_: str, **kwargs)[source]¶
Evaluates the metrics on the provided prediction and reference.
- Parameters:
prediction (Union[sitk.Image, np.ndarray]) – The prediction.
reference (Union[sitk.Image, np.ndarray]) – The reference.
id (str) – The identification of the case to evaluate.
- class pymia.evaluation.evaluator.Result(id_: str, label: str, metric: str, value)[source]¶
Bases:
objectRepresents a result.
- Parameters:
id (str) – The identification of the result (e.g., the subject’s name).
label (str) – The label of the result (e.g., the foreground).
metric (str) – The metric.
value (int, float) – The value of the metric.
- class pymia.evaluation.evaluator.SegmentationEvaluator(metrics: List[Metric], labels: dict)[source]¶
Bases:
EvaluatorRepresents a segmentation evaluator, evaluating metrics on predictions against references.
- Parameters:
metrics (list of pymia_metric.Metric) – A list of metrics.
labels (dict) – A dictionary with labels (key of type int) and label descriptions (value of type string).
- add_label(label: tuple | int, description: str)[source]¶
Adds a label with its description to the evaluation.
- Parameters:
label (Union[tuple, int]) – The label or a tuple of labels that should be merged.
description (str) – The label’s description.
- evaluate(prediction: Image | ndarray, reference: Image | ndarray, id_: str, **kwargs)[source]¶
Evaluates the metrics on the provided prediction and reference image.
- Parameters:
prediction (Union[sitk.Image, np.ndarray]) – The predicted image.
reference (Union[sitk.Image, np.ndarray]) – The reference image.
id (str) – The identification of the case to evaluate.
- Raises:
ValueError – If no labels are defined (see add_label).
The writer module (pymia.evaluation.writer)¶
The writer module provides classes to write evaluation results.
All writers inherit the pymia.evaluation.writer.Writer, which writes the results when
calling pymia.evaluation.writer.Writer.write(). Currently, pymia has CSV file
(pymia.evaluation.writer.CSVWriter and pymia.evaluation.writer.CSVStatisticsWriter) and
console writers (pymia.evaluation.writer.ConsoleWriter and pymia.evaluation.writer.ConsoleStatisticsWriter).
- class pymia.evaluation.writer.CSVStatisticsWriter(path: str, delimiter: str = ';', functions: dict | None = None)[source]¶
Bases:
WriterRepresents a CSV file evaluation results statistics writer.
- Parameters:
path (str) – The CSV file path.
delimiter (str) – The CSV column delimiter.
functions (dict) – The functions to calculate the statistics.
- write(results: List[Result], **kwargs)[source]¶
Writes the evaluation statistic results (e.g., mean and standard deviation of a metric over all cases).
- Parameters:
results (List[evaluator.Result]) – The evaluation results.
- class pymia.evaluation.writer.CSVWriter(path: str, delimiter: str = ';')[source]¶
Bases:
WriterRepresents a CSV file evaluation results writer.
- Parameters:
path (str) – The CSV file path.
delimiter (str) – The CSV column delimiter.
- write(results: List[Result], **kwargs)[source]¶
Writes the evaluation results to a CSV file.
- Parameters:
results (List[evaluator.Result]) – The evaluation results.
- class pymia.evaluation.writer.ConsoleStatisticsWriter(precision: int = 3, use_logging: bool = False, functions: dict | None = None)[source]¶
Bases:
WriterRepresents a console evaluation results statistics writer.
- Parameters:
precision (int) – The float precision.
use_logging (bool) – Indicates whether to use the Python logging module or not.
functions (dict) – The function handles to calculate the statistics.
- write(results: List[Result], **kwargs)[source]¶
Writes the evaluation statistic results (e.g., mean and standard deviation of a metric over all cases).
- Parameters:
results (List[evaluator.Result]) – The evaluation results.
- class pymia.evaluation.writer.ConsoleWriter(precision: int = 3, use_logging: bool = False)[source]¶
Bases:
WriterRepresents a console evaluation results writer.
- Parameters:
precision (int) – The decimal precision.
use_logging (bool) – Indicates whether to use the Python logging module or not.
- write(results: List[Result], **kwargs)[source]¶
Writes the evaluation results.
- Parameters:
results (List[evaluator.Result]) – The evaluation results.
- class pymia.evaluation.writer.ConsoleWriterHelper(use_logging: bool = False)[source]¶
Bases:
objectRepresents a console writer helper.
- Parameters:
use_logging (bool) – Indicates whether to use the Python logging module or not.
- class pymia.evaluation.writer.StatisticsAggregator(functions: dict | None = None)[source]¶
Bases:
objectRepresents a statistics evaluation results aggregator.
- Parameters:
functions (dict) – The numpy function handles to calculate the statistics.
- calculate(results: List[Result]) List[Result][source]¶
Calculates aggregated results (e.g., mean and standard deviation of a metric over all cases).
- Parameters:
results (List[evaluator.Result]) – The results to aggregate.
- Returns:
The aggregated results.
- Return type:
List[evaluator.Result]